Interpolasi Linear dan Spline sebagai Impute Handling Missing Values
Pendahuluan
Data yang hilang (missing data) merupakan permasalahan yang berpengaruh sebagian besar database tidak terkecuali rekam medis elektronik (EHR). Sebagian besar model statistik beroperasi hanya pada pengamatan lengkap dari variabel eksposur dan hasil, untuk itu dengan adanya missing data sangat mempengaruhi kinerja model. Sehingga perlunya penanganan missing data baik dengan cara menghapus data yang tidak lengkap (dropna) atau mengganti nilai yang hilang dengan prediksi nilai berdasarkan informasi lain yang tersedia. Proses mengganti nilai disebut sebagai imputasi (Cátia Salgado dkk, 2016). Pada penelitian ini penulis akan melakukan handling missing data dengan cara mengganti prediksi nilai berdasarkan informasi yang telah tersedia (impute). Penulis melakukan handling missing data berupa impute menggunakan teknik interpolasi.
Pada saat memperkirakan nilai tengah antara titik data yang tepat menggunakan metode interpolasi polinamial. Sedangkan untuk teknik Interpolasi dalam penelitian ini yaitu Intepolasi Linear dan Interpolasi Spline. Interpolasi Linear adalah bentuk paling sederhana karena hanya menghubungkan dua titik data dengan garis lurus. Konsep spline berawal dari teknik drafting dengan menggunakan strip tipis dan fleksibel (disebut spline) untuk menggambar kurva halus melalui sekumpulan titik (Steven dan Raymond, 2010).
Interpolasi Linear dan Spline pada penelitian ini bertujuan untuk mengetahui interpolasi yang paling baik. Skor pada Metode SVM, SGD, dan Random Forest digunakan dalam menilai kedua interpolasi tersebut. Penggunaan ketiga metode tersebut sebagai klasifikasi data, sehingga data yang digunakan harus disesuaikan juga.
Pada penelitian ini basis data yang digunakan yaitu Hepatitis C Virus (HCV), data tersebut diambil dari 615 pasien. Sebanyak 615 pasien terdapatatribut sebanyak 13 sebagai faktor yang mempengaruhi atrbbut target. Atribut kategori menjadi target pada penelitian ini, yang dapat diklasifikasikan beberapa kelas meliputi Blood Donor, Suspect Blood Donor, Hepatitis, Fibrosis, dan Cirrhosis.
Metode Penelitian
Metode penelitian yang harus diketahui terlebih dahulu yaitu jenis penelitian. Jenis penelitian kuantitatif dengan teknik pengumpulan data dan sumber data dilakukan dengan mengambil data sekunder yang diperoleh dari laman web (https://archive.ics.uci.edu/ml/datasets/HCV+data). Pada data tersebut terdapat missing data yang mengakibatkan proses analisa model tidak efisien, oleh karena itu dibutuhkan handling data. Handling data penelitian ini dengan cara impute yaitu dengan mengganti nilai yang hilang menggunakan interpolasi. Interpolasi Polinomial diketahui bahwa rumus umum untuk poliomial orde-n adalah

Untuk n+1 titik data, hanya ada satu dan hanya satu polynomial beroder n yang melewati semua titik. Penelitian ini akan menggunakan interpolasi linear dan spline, berikut formulasi dari linear interpolasi

Sedangkan untuk konsep spline berawal dari teknik drafting dengan menggunakan strip tipis dan fleksibel (spline) untuk menggambar kurva halus melalui sekumpulan titik. Spline yang diterapkan yaitu spline orde pertama atau spline linear, hubungan paling sederhana antara dua titik adalah garis lurus. Spline orde pertama untuk sekelompok titik data terurut dapat didefinisikan sebagai satu set fungsi linear,

Dimana nilai dari m1 adalah kemiringan garis lurus yang menghubungka titik — titik:

Persamaan diatas dapat digunakan sebagai evaluasi fungsi pada titik manapun antara x0dan x1 dengan terlebih dahulu mencari interval di mana titik tersebut berada. Kemudian persamaan yang sesuai digunakan untuk menentukan nilai fungsi dalam interval. Metode ini jelas identik dengan interpolasi linear.
Setelah dilakukan impute data menggunakan interpolasi data akan dilakukan skoring dengan model. Model yang digunakan diantaranya SVM, SGD dan Random Forest, dari ketiganya akan dilihat masing — masing skor pada setiap impute data. Pada penggunaan Metode SVM sendiri tujuannya untuk menemukan hyperplane optimal yang memaksimalkan celah atau margin antar kelas. Selanjutnya, menggunakan trik kernel untuk menemukan batas keputusan non-linear yang optimal antar kelas (Zaki dan Meira,2014), kernel SVM yang digunakan yaitu linear dengan formulanya sebagai berikut
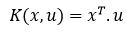
Metode selanjutnya adalah SGD( Stochastic Gradient Descent) merupakan metode penyederhanaan dari penghitungan gradien dalam setiap aproksimasi, untuk memperkirakan gradien berdasarkan pemilihan bobot awal secara acak (Bottou, 2012). Metode Stochastic Gradient Descent, diambil sebarang (wt) sebagai parameter, sehingga diperoleh persamaan sebagai berikut
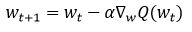

Hasil dan Pembahasan
Hasil dan pembahasan dalam penelitian ini dengan data Hepatitis C Virus dan target klasifikasinya adalah atribut kategori menggunakan tiga metode yang berbeda. Ketiga metode yang digunakan untuk melihat skor interpolasi paling baik dilakukan perlakuan sama yaitu pada splitting data, rasio perbandingan data training dan testing 6 : 4 serta random state 0. Sehingga dapat ditulis kedalam sebuah tabel dan grafik sebagai berikut.
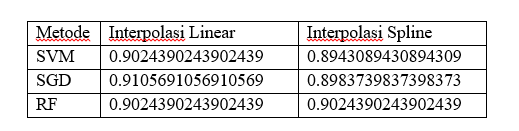
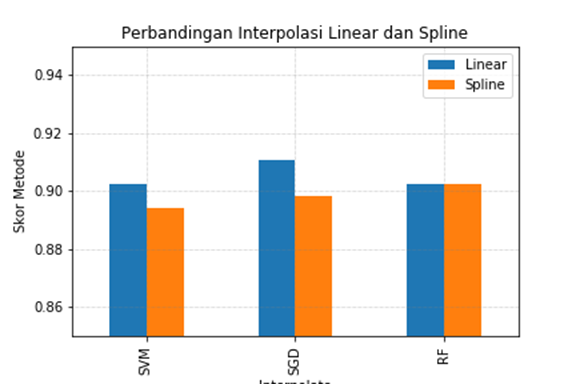
Tabel 1 menunjukkan bahwa skor Interpolasi Linear sedikit lebih unggul dari Interpolasi Spline pada saat menggunakan Metode SVM maupun SGD, akan tetapi hasil dari Metode RF (Random Forest) relatif sama. Hal ini dapat terlihat jelas lagi jika disajikan pada diagram batang sebagai berikut :
Kesimpulan
Analisa hasil dari pembahasan diatas dapat ditarik kesimpulan bahwa Interpolasi Linear jauh lebih unggul daripada Spline pada Data Hepatitis C Virus (HCV) dengan ukuran data (615,14). Akan tetapi kedua interpolasi tersebut harus dilakukan penelitian lebih lanjut lagi dan diimplementasikan pada data — data yang ukurannya jauh lebih besar maupun lebih kecil agar diperoleh hasil yang baik.
Daftar Pustaka
Awad, M., & Khanna, R. (2015). Support vector machines for classification. In Efficient Learning Machines (pp. 39–66). Apress, Berkeley, CA.
Bottou, L. (2012). Stochastic gradient descent tricks. In Neural networks:Tricks of the trade (pp. 421–436). Springer, Berlin, Heidelberg.
Chapra, S. C., & Canale, R. P. (2010). Numerical methods for engineers. Boston: McGraw-Hill Higher Education,
Cutler, A., Cutler, D. R., & Stevens, J. R. (2012). Random forests. In Ensemble machine learning (pp. 157–175). Springer, Boston, MA.
Salgado, C. M., Azevedo, C., Proença, H., & Vieira, S. M. (2016). Missing data. Secondary Analysis of Electronic Health Records, 143–162.
Zaki, M. J., Meira Jr, W., & Meira, W. (2014). Data mining and analysis: fundamental concepts and algorithms. Cambridge University Press.
